Traffic count data anomaly detection
Sector:
Data science
The context:
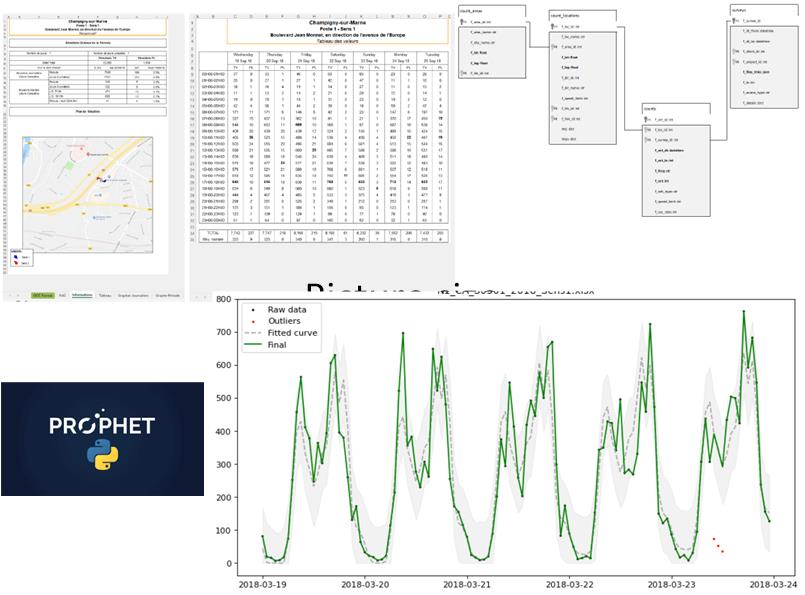
Our client operates the road network in the Val-de-Marne department, bordering Paris. Over the past years, they contracted multiple suppliers to survey vehicle counts on their network. This data has been provided in different formats for each supplier, and for some of them, no quality checks were carried out on the final data. Our client wanted to consolidate all this data into a unified database and implement automated testing to verify the quality of the count data and, where possible, automatically correct the outliers.
What we did:
We first developed dedicated scripts to ingest the data from the various suppliers. Over 1,000 Excel files were ingested, with their relevant information extracted and structured. We developed a machine learning process based on time-series analysis to detect inconsistencies and outliers in the data. When possible, we corrected the data using trends derived from past and future observations. We delivered a structured, unified database containing all historical count data, maintaining both the raw and corrected data.
The value for our client:
The information provided by several suppliers over the past years could now be evaluated, checked, and reused. Our client can use the structured and corrected data in their own GIS environment, allowing them to query all their historical traffic count data from a single source. This has made appraising their traffic reduction policy much easier and more scientific.