Détection d’anomalies de données de trafic routier
Secteur:
Data science
Simulation dynamique du flux d’arrivées d’étudiants
Le contexte :
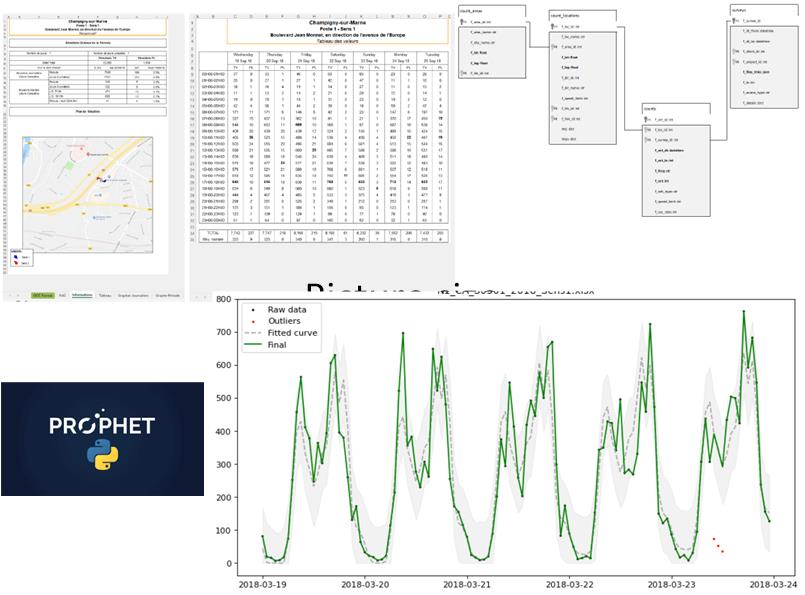
Notre client gère le réseau routier dans le département du Val-de-Marne, limitrophe de Paris. Au cours des dernières années, il a fait appel à plusieurs prestataires pour effectuer des comptages de véhicules sur son réseau. Ces données ont été fournies dans différents formats selon les prestataires, et pour certaines d’entre elles, aucun contrôle de qualité n’a été réalisé sur leur communication finale.
Notre client souhaitait regrouper toutes ces données dans une base de données unifiée et mettre en place des tests automatisés pour vérifier leur cohérence et, lorsque cela était possible, corriger automatiquement les valeurs aberrantes.
Notre apport :
Nous avons d’abord développé des scripts dédiés pour ingérer les données provenant des différents prestataires. Plus de 1 000 fichiers Excel ont été intégrés, avec les informations pertinentes extraites et structurées.
Nous avons développé un processus d’apprentissage automatique basé sur l’analyse des séries temporelles pour détecter les incohérences et les valeurs aberrantes dans les données. Lorsque cela était possible, nous avons corrigé les données en nous basant sur les tendances observées dans les données passées et futures. Nous avons livré une base de données unifiée et structurée contenant toutes les données historiques de comptage, en conservant à la fois les données brutes et corrigées.
Les bénéfices pour notre client :
Les informations fournies par plusieurs prestataires au fil des années ont pu être valorisées, vérifiées et réutilisées. Notre client peut désormais utiliser les données structurées et corrigées dans son propre environnement SIG, ce qui lui permet d’interroger toutes ses données historiques de comptage de trafic à partir d’une seule source. Cela a considérablement simplifié et rendu plus scientifique l’évaluation de leur politique de réduction du trafic.